


通过分析网站的日志和搜索引擎蜘蛛的爬行记录可以有效的分析网站的运行动态还是有必要的。我们一般的站长会使用一些插件来进行获取蜘蛛的爬行数据在网站后台进行分析。当然,安装太多的插件可能会降低网站的访问速度和运行效率,所以老蒋一般的建议是能不安装插件就不安装,如果有代码可以实现的就直接用代码实现。

这里我们将代码记录如下:
// 代码获取蜘蛛爬行记录日志 https://www.itbulu.com/wp-bots-logs.html
function get_naps_bot(){
$useragent = strtolower($_SERVER['HTTP_USER_AGENT']);
if (strpos($useragent, 'googlebot') !== false){
return 'Googlebot';
}
if (strpos($useragent, 'msnbot') !== false){
return 'MSNbot';
}
if (strpos($useragent, 'slurp') !== false){
return 'Yahoobot';
}
if (strpos($useragent, 'baiduspider') !== false){
return 'Baiduspider';
}
if (strpos($useragent, 'sohu-search') !== false){
return 'Sohubot';
}
if (strpos($useragent, 'lycos') !== false){
return 'Lycos';
}
if (strpos($useragent, 'robozilla') !== false){
return 'Robozilla';
}
return false;
}
function nowtime(){
date_default_timezone_set('Asia/Shanghai');
$date=date("Y-m-d.G:i:s");
return $date;
}
$searchbot = get_naps_bot();
if ($searchbot) {
$tlc_thispage = addslashes($_SERVER['HTTP_USER_AGENT']);
$url=$_SERVER['HTTP_REFERER'];
$file="robotslogs.txt";
$time=nowtime();
$data=fopen($file,"a");
$PR="$_SERVER[REQUEST_URI]";
fwrite($data,"Time:$time robot:$searchbot URL:$tlc_thispage\n page:$PR\r\n");
fclose($data);
}
把代码添加到当前主题的 Functions.php 文件中,如果没有异常或者不兼容,我们才可以。
我们检查站点根目录是否有 "robotslogs.txt"文件,如果有的话就可以,且可以设置777权限,这个是用来记录搜索引擎蜘蛛爬虫记录的。以后我们直接打开这个文件就可以看到。如果我们希望修改这个文件名,直接在上面代码中替换成自己熟悉的名称。
本文出处:老蒋部落 » 无需插件获取WordPress各大搜索引擎蜘蛛爬行记录且生成日志文件 | 欢迎分享( 公众号:老蒋朋友圈 )

 LeWeChatFans - 公众号涨粉引流插件 定时弹出遮罩
LeWeChatFans - 公众号涨粉引流插件 定时弹出遮罩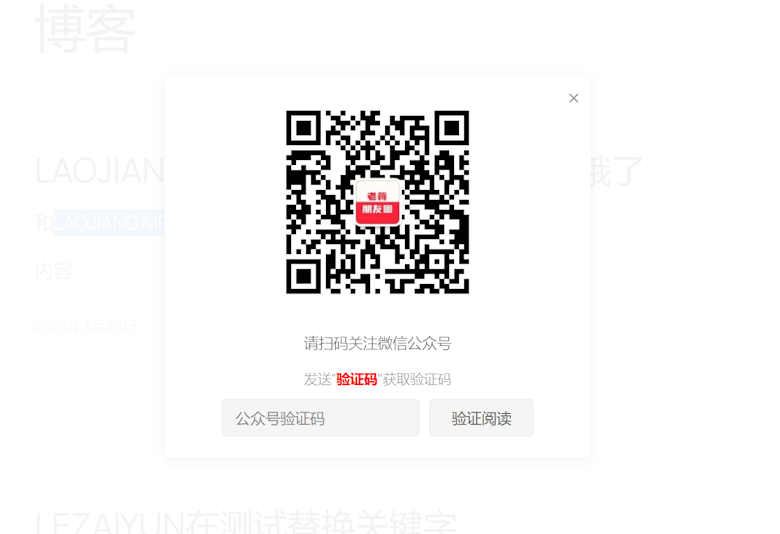 LeWeChatCopy - 一款免费适用WordPress复制关注公众号插件
LeWeChatCopy - 一款免费适用WordPress复制关注公众号插件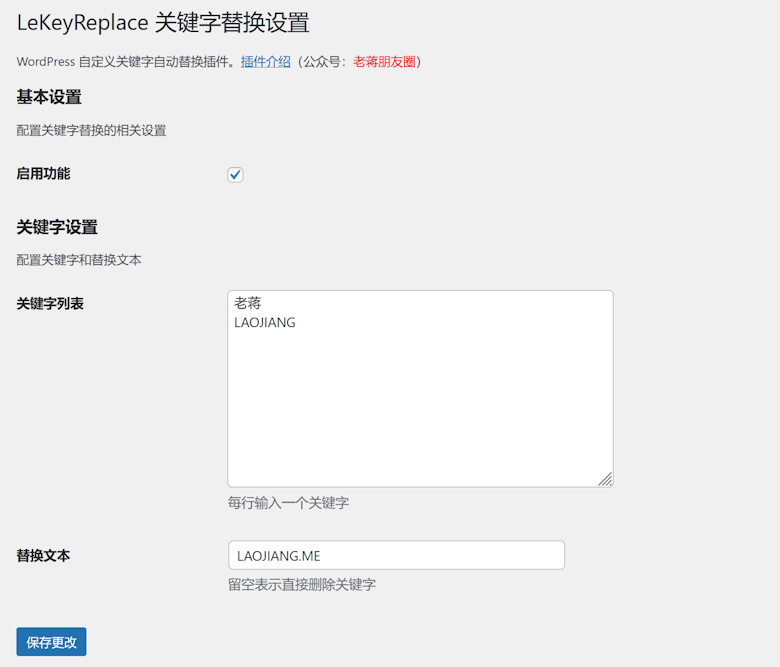 LeKeyReplace - 一款WordPress自动替换敏感关键字的插件
LeKeyReplace - 一款WordPress自动替换敏感关键字的插件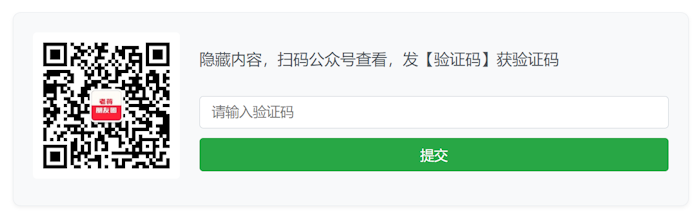 这款免费的WordPress关注公众号涨粉插件值得推荐
这款免费的WordPress关注公众号涨粉插件值得推荐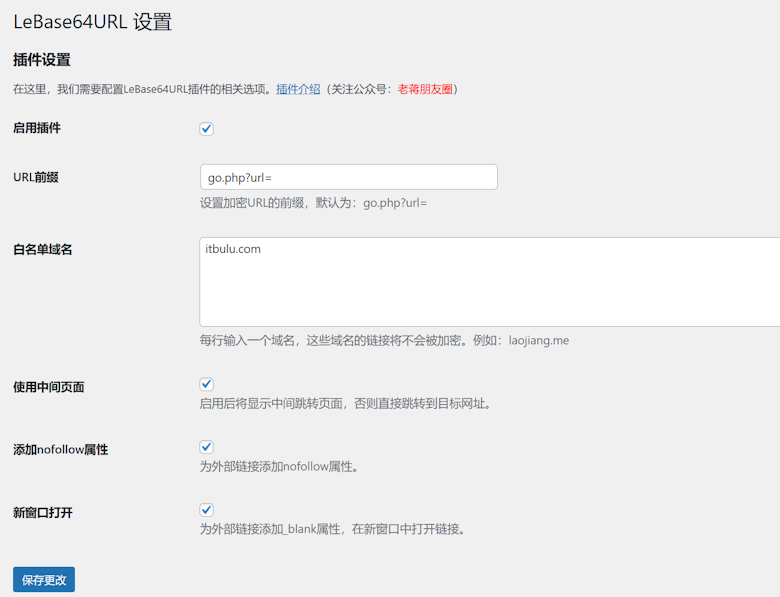 LeBase64URL 插件实现WordPress外部链接加密隐藏
LeBase64URL 插件实现WordPress外部链接加密隐藏 WordPress批量自动匹配TAG标签到文章利于SEO内链
WordPress批量自动匹配TAG标签到文章利于SEO内链






